Lerntagebuch
Willkommen zu meinem Lerntagebuch
Posts
-
Schlussartikel
Nun da das Semester (fast) vorbei ist, ist die Zeit gekommen auf die gelernten Inhalte zurückzublicken. Ich glaube es ist sogar das erste Mal, dass ich mich so bewusst Frage “Was habe ich eigentlich alles gelernt?” und “Was hätte ich mir sonst noch gewünscht?”. Klar mache ich mir solche Überlegungen auch bei einer Unterrichtsbeurteilung, aber halt eher oberflächlich. Aber gut, fangen wir an:
-
Tag 10 - Linked Data
In der letzten Unterrichtseinheit beschäftigten wir uns mit den aktuellen Datenmodelle (BIBFRAME und Records in Context) für Metadaten im Linked Data Bereich. Es folgte ein Input einer Kollegin zu Alma. Danach konnten wir aus einer interessanten Auswahl an Praxisberichten auswählen, von welchem wir gerne mehr gehört hätten. Ich gehe hier vor allem auf die beiden Datenmodelle ein.
-
Tag 9 - Suchmaschinen und Discovery-Systeme 2
In der Sitzung vom 11.12.2020 haben wir uns ein weiteres Mal mit Suchmaschinen und Discovery-Systemen auseinandergesetzt. Um ehrlich zu sein, fand ich die Übungen in dieser Vorlesung eher schwierig umzusetzen. Ich bin mir auch nicht sicher, ob ich das was ich in den folgenden Abschnitten zusammenfasse, ganz richtig verstanden habe.
-
Tag 8 - Suchmaschinen und Discovery-Systeme 1
In der 8. Sitzung sollten wir uns mit Suchmaschinen und Discovery-Systemen auseinandersetzen. Dazu soll VuFind installiert und konfiguriert werden. Zuerst gab es aber noch einen Nachtrag zum Modellieren der Metadaten und zur Nutzung der Schnittstellen.
-
Tag 7 - Metadaten modellieren und Schnittstellen nutzen 2
Als Vorbereitung auf die heutige Sitzung sollten die Studierenden die Lehrmaterialien von Library Carpentry zu OpenRefine durcharbeiten.
Im Unterricht erhielten wir eine Einführung in OpenRefine, gefolgt von zwei Übungen. Ausserdem wurde das Schaubild aktualisiert. OpenRefine wurde darin aufgenommen.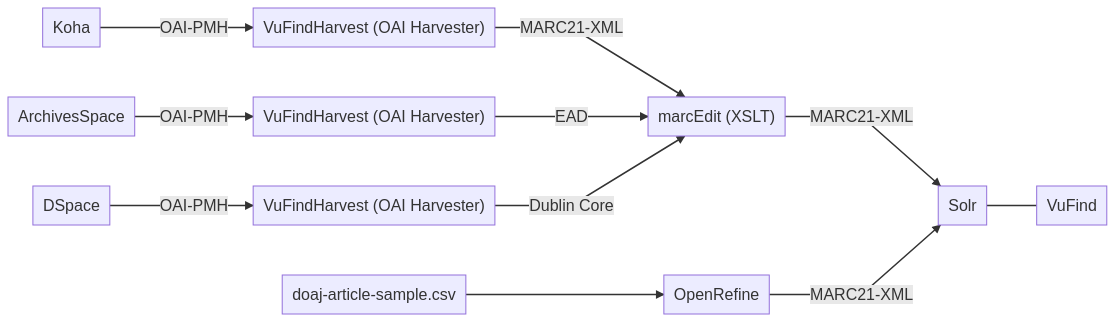
-
Tag 6 - Metadaten modellieren und Schnittstellen nutzen 1
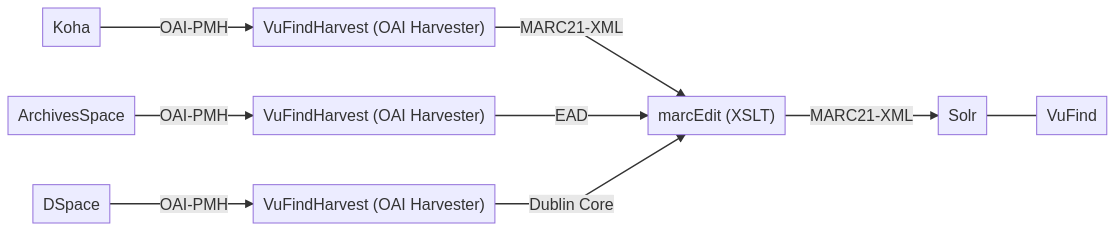 Das Schaubild soll uns Studierenden zeigen, wie weit wir im Kurs vorangekommen sind. Aus platz- und zeichengründen habe ich dieses bis jetzt noch nicht erwähnt, gehe aber nun etwas darauf ein:
Das Schaubild soll uns Studierenden zeigen, wie weit wir im Kurs vorangekommen sind. Aus platz- und zeichengründen habe ich dieses bis jetzt noch nicht erwähnt, gehe aber nun etwas darauf ein:
Wir haben uns bereits das Bibliothekssystem Koha, das Archivsystem ArchivesSpace und die Repository-Softwares DSpace angeschaut, Datensätze erstellt und einige Dinge ausprobiert. Heute stand das “Harvesten” und Konvertieren der Metadaten auf dem Plan. Das “Harvesten” soll mit dem OAI Harvester “VuFindHarvest” geschehen. Dabei soll von Koha das Format MARC21-XML, von ArchivesSpace EAD und von DSpace Dublin Core geharvestet werden. Mit dem Programm MarcEdit (XSLT) sollen die EAD und Dublin Core Daten in MARC21-XML konvertiert werden. -
Tag 5 - Funktion und Aufbau von Archivsystemen 2 & Repository-Software für Publikationen und Forschungsdaten 1
Am Tag 5 der BAIN-Vorlesungen haben wir uns abschliessend mit den Archivsystemen auseinandergesetzt. Die Übung vom letzten Mal wurde besprochen, ein Datenimport und –export wurde durchgeführt und ein Marktüberblick über die Archivsysteme wurde gegeben. Danach wendeten wir uns den Repository-Softwares für Publikationen und Forschungsdaten zu. So lernte ich DSpace kennen. Dort haben wir ebenfalls zwei Übungen gemacht. Zum Schluss gab es wiederum einen Marktüberblick zu den Repository Softwares.
In diesem Beitrag setze ich mich nochmals mit ArchivesSpace auseinander. Durch die heutige Vorlesung wurde mir nämlich klar, dass ich das Prinzip von ArchivesSpace in der Übung letztes Mal gar nicht richtig verstanden habe. DSpace wird nur ganz kurz abgehandelt. -
Tag 4 - Funktion und Aufbau von Archivsystemen 1
Die heutige Unterrichtseinheit begann mit den Metadatenstandards in Archiven. Zum einen gibt es ISAD(G) und zum anderen EAD. Danach haben wir einige Eckdaten zu ArchivesSpaces erhalten und in einer Übung Datensätze erstellt.
-
Tag 3 - Funktion und Aufbau von Bibliothekssystemen 2
In der heutigen Einheit sollen die Studierenden das Bibliothekssystem Koha besser kennenlernen. Dazu sind vor allem Übungen gedacht. Die erste Übung befasst sich mit der manuellen Bedienung des Systems. In der zweiten Übung soll ein Datenimport durchgeführt werden. In der dritten und letzten Übung soll eine Schnittstelle für den Datenexport aktiviert werden.
-
Tag 2 - Funktion und Aufbau von Bibliothekssystemen 1
Bei der zweiten Vorlesung in BAIN sollte es nun endlich um Bibliothekssysteme gehen. Als erstes sollte aber anhand eines Beispiels, das jede*r Teilnehmer*in ausführen sollte, das Versionskontrollsystem Git demonstriert werden. Danach gab es eine kurze Auffrischung in dem - zumindest in Bibliotheken - verbreitetsten Metadatenstandard MARC21 sowie dem bekannten Dublin Core. Zum Schluss ging es an die Installation und Konfiguration von Koha.
-
Tag 1 - technische Grundlagen
In der ersten Vorlesung des Moduls Bibliotheks- und Archivinformatik wurde viel Organisatorisches besprochen, alle wurden einander vorgestellt und ein erster Einblick in die Lerninhalte ist erfolgt. Viel neues wurde dabei leider nicht angeschaut. Sehr ansprechend war die Plattform CodiMD sowie die Auszeichnungssprache Markdown. Die Grundlagen zum Umgang mit einer virtuellen Maschine, Ubuntu, der Unix Shell und GitHub wurde bereits in anderen Modulen behandelt. Allerdings waren, so viel mir ist, nicht alle Personen in diesen Modulen, weshalb es sicher sinnvoll ist diese Grundlagen am Anfang nochmals zu wiederholen.
-
Einführungsartikel
Wo bin ich gestartet?
subscribe via RSS