Tag 7 - Metadaten modellieren und Schnittstellen nutzen 2
Als Vorbereitung auf die heutige Sitzung sollten die Studierenden die Lehrmaterialien von Library Carpentry zu OpenRefine durcharbeiten.
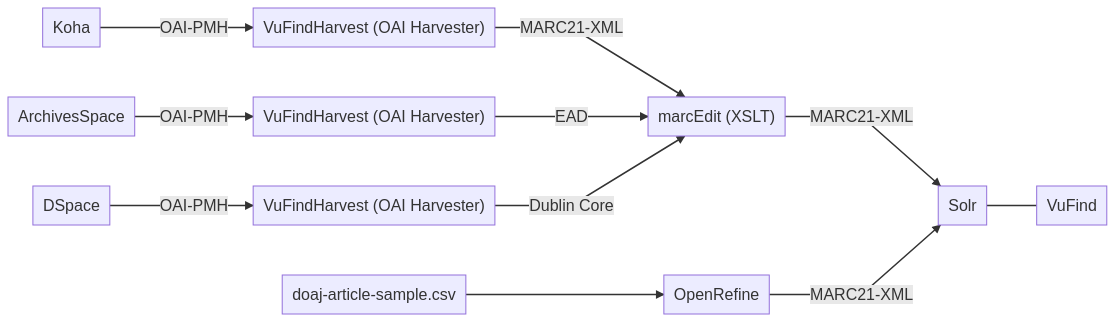
Im Unterricht erhielten wir eine Einführung in OpenRefine, gefolgt von zwei Übungen. Ausserdem wurde das Schaubild aktualisiert. OpenRefine wurde darin aufgenommen.
Vorbereitungsauftrag OpenRefine
- Als “seperator Character” eignet sich “|”, da dieses Symbol in Datensätzen sehr selten verwendet wird. Komma, Semikolon, Doppelpunkte usw. werden dagegen in Datensätzen verwendet und eignen sich nicht.
- Text Facet: Gruppierung von Textwerten –> zählt wie oft ein Wert vorkommt, gruppiert sie zusammen und zeigt an, wie oft er vorkommt.
- Numeric und Timline Facets: zeigen Graphen anstatt einer Liste mit Werten
- Filter: Suche nach bestimmten Zeichen/Text
- Clustering: Gibt Daten aus, die dieselben sein könnten. Z. B. unterschiedliche Schreibweise von Autoren, kann man dann manuell zusammenfügen
- Transformation: Geht weiter als Facets, Filter und Clustering. Wenn man bspw. Adresse in unterschiedliche Teile aufsplitten möchte, ein Datenformat standardisieren möchte, ohne die Werte zu verändern od. einen bestimmten String aus einem längeren Datensatz extrahieren. Wird mit der Sprache “GREL” gemacht.
Die Lehrmaterialien sind sehr gut aufbereitet, ich konnte (fast) alle Übungen schnell und ohne Probleme durcharbeiten. Einzig bei der “Introduction to Transformations” hat es bei mir keine zwei gleichen Facets bei den Publisher gegeben, weshalb ich diese Übung übersprungen habe.
Ich fand die Software sehr beindruckend. Mit wenigen Klicks konnten sehr viele Daten zielführend bearbeitet werden. Cool wäre natürlich, wenn sie dazu auch noch kollaborativ wäre.
OpenRefine
OpenRefine ist ein kostenloses, open-source Tool, um mit “messy data” zu arbeiten. Und weil sie unordentlich sind müssen sie natürlich aufgeräumt werden… :) Genau das kann mit OpenRefine gemacht werden: wenn bspw. bestimmte Begriffe unterschiedlich geschrieben werden, können diese ganz einfach vereinheitlicht werden. Aber auch die Transformation von einem Datenformat in ein anderes ist möglich oder die eigenen Daten mit anderen Daten aus dem Web anzureichern. In der Praxis wird OpenRefine vor allem für die Bereinigung von Daten verwendet, oft auch für die Datentransformation oder für die Vorbereitung, um Daten in ein anderes System zu laden. Geeignet ist das Tool v. a. für tabellarische Daten (csv, tsv, xls, xlsx) und einfaches XML (z. B. MARCXML). Zudem ist es für den lokalen Einsatz angelegt.
Übung 1: CSV nach MARCXML
Bei OpenRefine kann das Template für den Crosswalk selbst bearbeitet werden. Es wird verwendet, wenn das gewünschte Format nicht zum Export zur Verfügung steht. Gearbeitet wird mit GREL-Befehlen.
In dieser Übung soll der von den Dozierenden vorgegebene Code untersucht werden: Was geschieht mit den Eingabedaten? Wie unterscheiden sich die Ausgabedaten von ihnen?
Herausgefunden habe ich dabei folgendes:
- Im Leader steht immer “ nab a22 uu 4500”, dies ist hartcodiert
- Tag 001: URL wird übernommen, aber nur das was am Ende steht –> Artikel wird herausgeschnitten
- Tag 022: ISSN wird übernommen
- Tag 100: 1. Autor’inn, wird gesplittet beim Zeichen ‘|’, Autor’innen werden in ein Array geschrieben und 1. Person wird ausgelesen
- Tag 245: Titel wird übernommen
- Tag 700a: alle weiteren Autor’innen werden übernommen
value.escape(‘xml’): Alle Zeichen, die es nicht im XML gibt, werden in XML ausgedrückt: bspw. ‘&’ wird dann einfach anders geschrieben, so dass man weiss, dass es ein kaufmännisches und ist.
Übung 2: Template ergänzen
Als zweite Übung durften wir uns an einem eigenen Template versuchen, oder zumindest das vorhandene erweitern, so dass weitere in den Daten vorhandene Informationen in ein ausgewähltes MARC21-Feld übernommen werden konnten.
In unserer Gruppe entschieden wir uns dazu, die Daten aus den Zellen ‘Subjects’ zu exportieren. Dazu konnte eigentlich beinahe der Code, den die Dozierenden für die Autor’innen verwendet haben, benutzt werden. Natürlich musste die Tag-Nummer ersetzt werden und der Indikator 2 musste leer bleiben. Ausserdem mussten die ‘Subejcts’ nicht auf unterschiedliche Tags aufgeteilt werden. Nachfolgend ist das abgeänderte Template zu sehen:
{{
forEach(cells[‘Subjects’].value.split(‘|’), v ,’
<datafield tag=”650” ind1=”0” ind2=” “>
<subfield code=”a”>’ + v.escape(‘xml’) + ‘</subfield>
</datafield>’)
}}