Tag 10 - Linked Data
In der letzten Unterrichtseinheit beschäftigten wir uns mit den aktuellen Datenmodelle (BIBFRAME und Records in Context) für Metadaten im Linked Data Bereich. Es folgte ein Input einer Kollegin zu Alma. Danach konnten wir aus einer interessanten Auswahl an Praxisberichten auswählen, von welchem wir gerne mehr gehört hätten. Ich gehe hier vor allem auf die beiden Datenmodelle ein.
Als erstes ging es aber noch einmal um die Discovery-Systeme. Dabei habe ich gelernt, dass eben nicht nur das Discovery System wie bspw. Primo oder VuFind gekauft werden muss, sondern auch ein Central Index. Primo hat z. B. einen eigenen. Darin sind die Daten enthalten und er wird in den Katalog eingebunden. Die Daten besitzt man dabei nicht selbst. Ein Discovery System ohne Central Index nützt also nicht sehr viel.
Aktuelle Datenmodelle für Metadaten
BIBFRAME
Die Initiative BIBFRAME wurde vor noch nicht allzu langer Zeit (laut LOC 2012, laut DNB 2011) von der Library of Congress ins Leben gerufen, mit dem Ziel MARC 21 abzulösen. Dieses ist ein Format, das darauf fokussiert ist, Datensätze zu erstellen, die ein einzelnes Objekt beschreiben. Es wird keine Kontextinformation benötigt: jedes Objekt steht für sich, es gibt keine Beziehungen zu andere Datensätzen. Für einen Katalog mag dies okay sein, aber für das Datenmanagement nicht. Eine bessere Lösung wäre eben BIBFRAME. Ein weiterer Grund für ein neues Datenmodell war die Einführung von RDA als neues Regelwerk für die Katalogisierung in Bibliotheken.
BIBFRAME steht für Bibliographic Framework und soll auch die Möglichkeiten von Linked-Data- und Semanitc-Web-Technologien berücksichtigen. Das Datenmodell stellt Datensätze also in Verbindung miteinander. Dabei besteht es aus dem BIBFRAME Model und dem BIBFRAME Vocabulary.
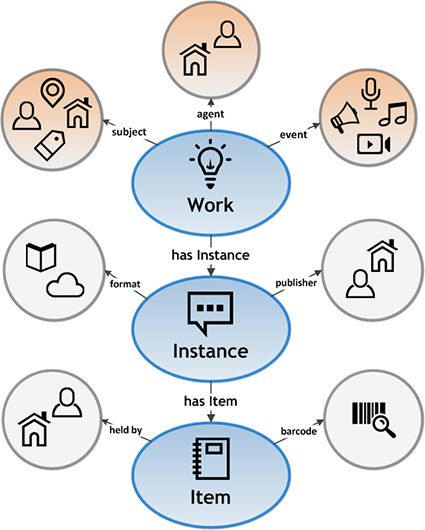
Wie auf dem Bild des Datenmodells zu sehen ist, wird in drei Abstraktionsebenen unterschieden:
- Work: Konzeptueller Kern der katalogisierten Ressource. Enthält Angaben zu Autor’innen, Sprache und Thema.
- Instance: Ein Werk hat unterschiedliche Erscheinungsweisen, diese sind dann die Instanzen eines Werkes. Enthält Angaben wie verlegenden Person, Ort und Datum der Publikation und Format.
- Item: Tatsächliche physisches oder elektronisches Exemplar der Instanz, die dann in einer Bibliothek vorhanden ist. Enthält Angaben wie Standort, Barcode und Regal.
Ich bin leider keine RDA-Expertin, und habe nur durch unseren Bibliothekskatalog Kontakt damit, aber dieser Aufbau erinnert mich stark an den von RDA. Dies würde natürlich auch Sinn machen, da das Datenmodell auf RDA aufbaut.
Das BIBFRAME Vocabulary ist eine Ontologie, die “Classes” und dazugehörige “Properties” enthält. Sie übernimmt die Konzepte von RDA.
Records in Context (RiC)
RiC ist eigentlich dasselbe wie BIBFRAME einfach für Archive. Es basiert ebenfalls auf Linked-Data-Prinzipien. Es soll neue und mehrfache Beziehungen zwischen Entitäten ermöglichen.
RiC besteht ebenfalls aus einem Modell (RiC-CM) und einer Ontologie (RiC-O). Das Modell basiert auf Entitäten (Schriftgut, Funktion, Akteur’innen etc.), deren Properties (ID, Name, Beschreibung etc.) und den Beziehungen zwischen ihnen. Also kann bspw. gesagt werden, dass ein Schriftgut von einer Akteurin erstellt wurde.
Bei der Ontologie sind laut Dozenten alle Entitäten und das Vokabular verzeichnet, aber es ist noch nicht ganz ausgereift.
Zur Konvertierung ist die OpenSource Software RiC-O Converter vorhanden, die kostenlos und frei zugänglich ist.
Laut den Dozierenden werden wohl die meisten in der Archivwelt irgendwann auf RiC umsteigen - alle warten auf die “next generation” Archivsysteme. Die Arbeitsweise im Archiv wird sich also verändern.